


White Papers/Reports
eCOA Go-Live Readiness in Clinical Trials
Learn how a readiness-first eCOA approach improves clinical trial startup timelines, reduces delays, and protects…

eCOA Strategy Playbook for Emerging Biopharma Clinical Trials
Learn how to build an effective eCOA strategy, evaluate platforms, and scale eCOA to support…

The Rare Disease eCOA Playbook
Rare disease clinical trials require precision, flexibility, and patient-first thinking. YPrime’s Rare Disease eCOA Playbook…

The eCOA Oncology Playbook
Learn how to select and implement the right eCOA platform for the complex demands of…

eCOA Joint Assessments—How Purpose-Built eCOA Improves Data Quality in Clinical Trials
Learn how purpose-built eCOA solutions transform clinical trials beyond simple digitization…
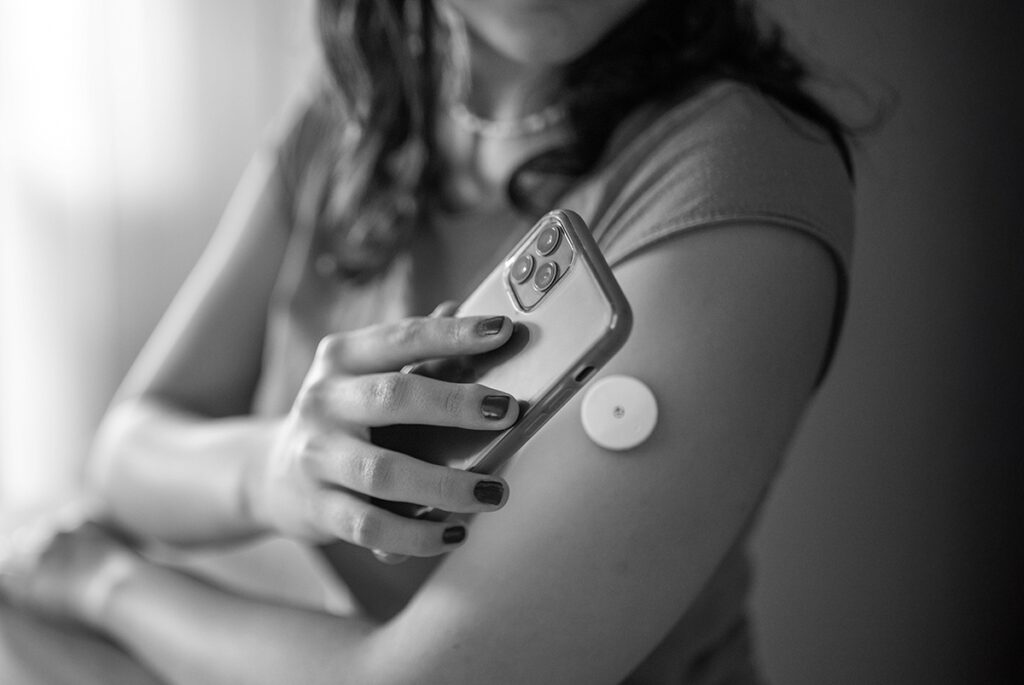
eCOA and Connected Devices: Power Real-Time, Patient-Centered Clinical Trials
Discover how integrated eCOA and connected devices enable real-time, patient-centered clinical trials—improving data quality, reducing…
Videos



We’ve got you covered with strategies and solutions to improve your clinical trial technology, reduce clinical research site burden, and transform your patient experience.
Let’s get started today!