


White Papers/Reports

Digital Joint Assessments—How Purpose-Built eCOA Solutions Improve Clinical Research
Learn how purpose-built eCOA solutions transform clinical trials beyond simple digitization…
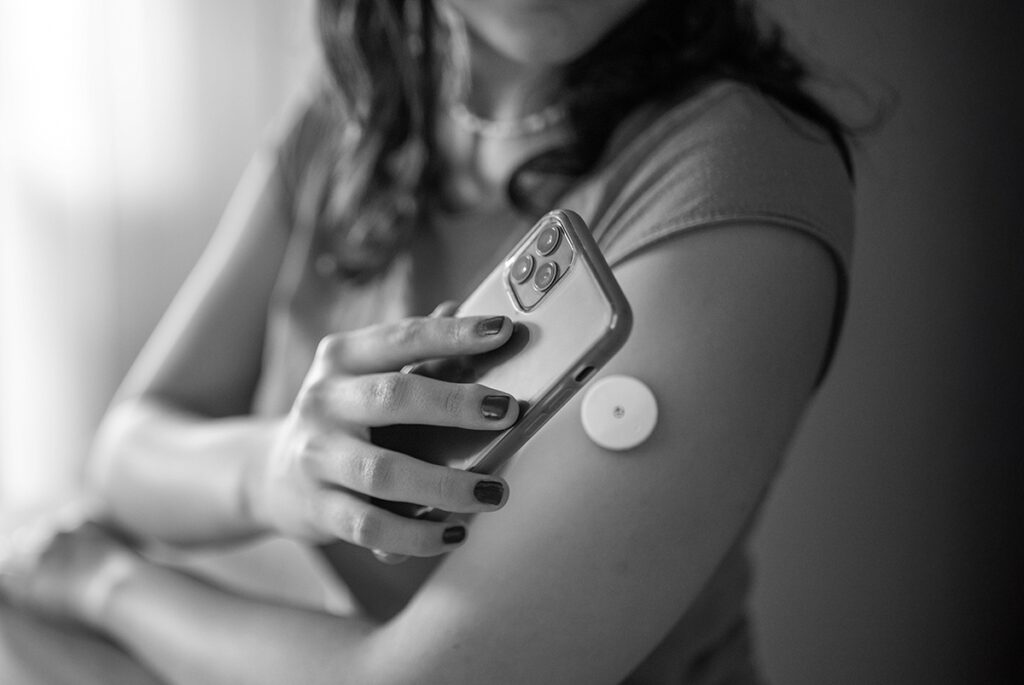
eCOA and Connected Devices: Power Real-Time, Patient-Centered Clinical Trials
Discover how integrated eCOA and connected devices enable real-time, patient-centered clinical trials—improving data quality, reducing…

The CRO’s Playbook for eCOA Success
Leading CROs don’t just deploy technology—they build solutions that win business. This playbook provides a…

Optimizing eCOA for Pain Management Studies—Your Selection Guide
This comprehensive playbook provides a practical framework for navigating the eCOA selection process…
Your Essential Guide—eCOA Licensing and Translation
Do you struggle managing clinical trial licensing and translation for your eCOA…

8 eCOA Strategies for More Efficient Studies
This succinct roadmap offers data-driven actions to manage timelines, enhance data quality, and improve eCOA…
Videos



We’ve got you covered with strategies and solutions to improve your clinical trial technology, reduce clinical research site burden, and transform your patient experience.
Let’s get started today!